SUM: A Benchmark Dataset of Semantic Urban Meshes
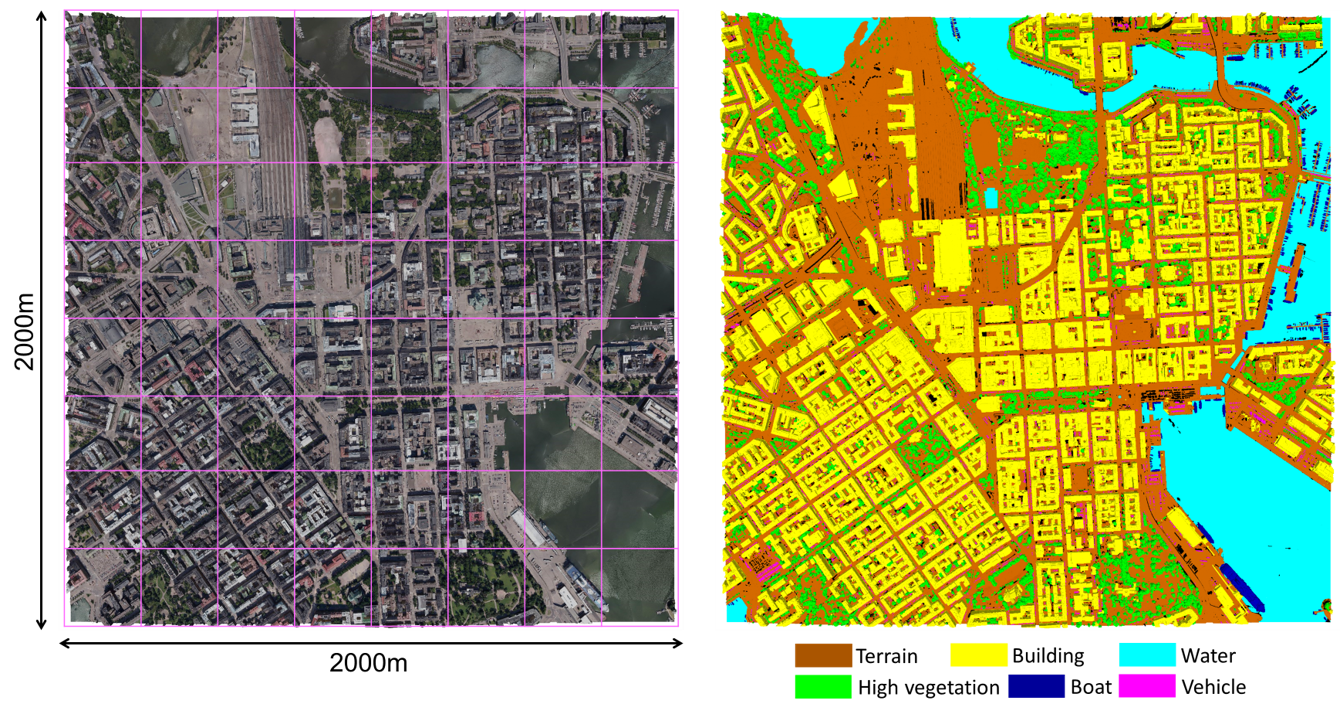
Figure 1: Overview of the semantic urban mesh benchmark. Left: the textured meshes. Right: the ground truth meshes.
- Summary
- Data Download
- Source Code
- Labelling Workflow
- Comparison of Existing 3D Urban Benchmark Datasets
- Data Split
- Evaluation
- Video Demo
- Citation
- Funding
- Team
- Student Helper
Summary
We introduce a new benchmark dataset of semantic urban meshes which covers about 4 km2 in Helsinki (Finland), with six classes: Terrain, Vegetation, Building, Water, Vehicle, and Boat.
We have used Helsinki 3D textured meshes as input and annotated them as a benchmark dataset of semantic urban meshes. The Helsinki's raw dataset covers about 12 km2 and was generated in 2017 from oblique aerial images that have about a 7.5 cm ground sampling distance (GSD) using an off-the-shelf commercial software namely ContextCapture.
The entire region of Helsinki is split into tiles, and each of them covers about 250 m2. As shown in the figures below, we have selected the central region of Helsinki as the study area, which includes 64 tiles.
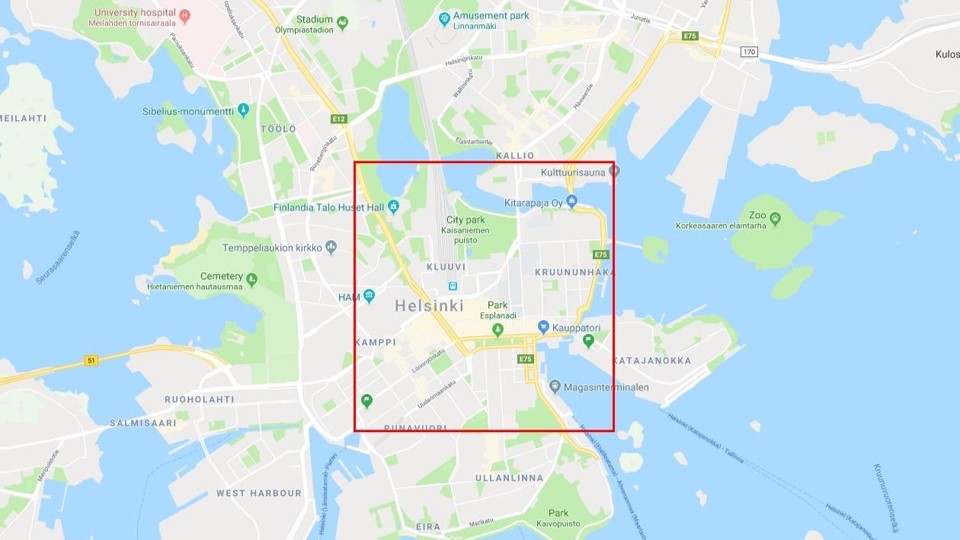
Figure 2: Selected area of Helsinki
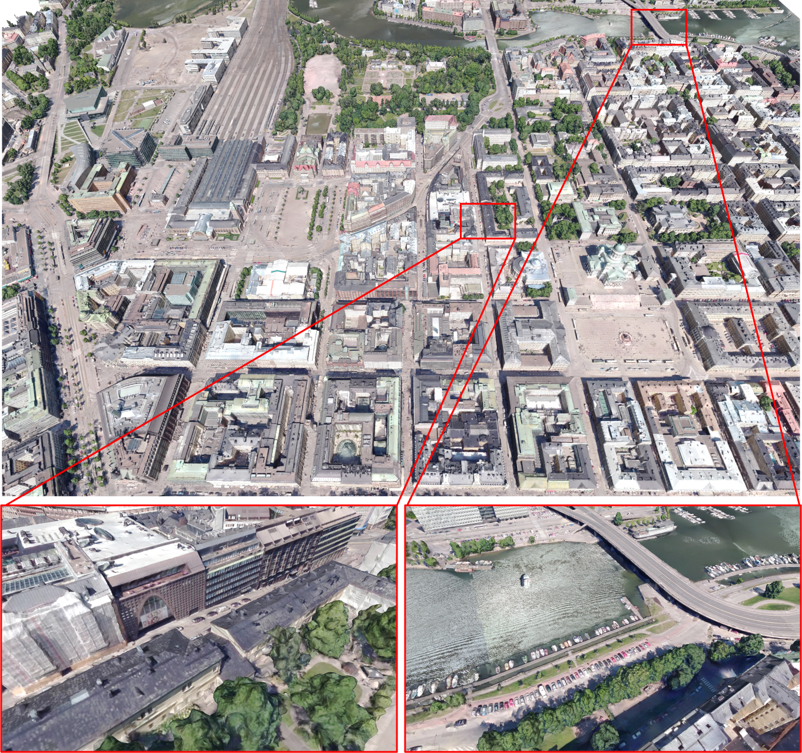
Figure 3: Part of the semantic urban mesh benchmark dataset shown as a texture mesh.
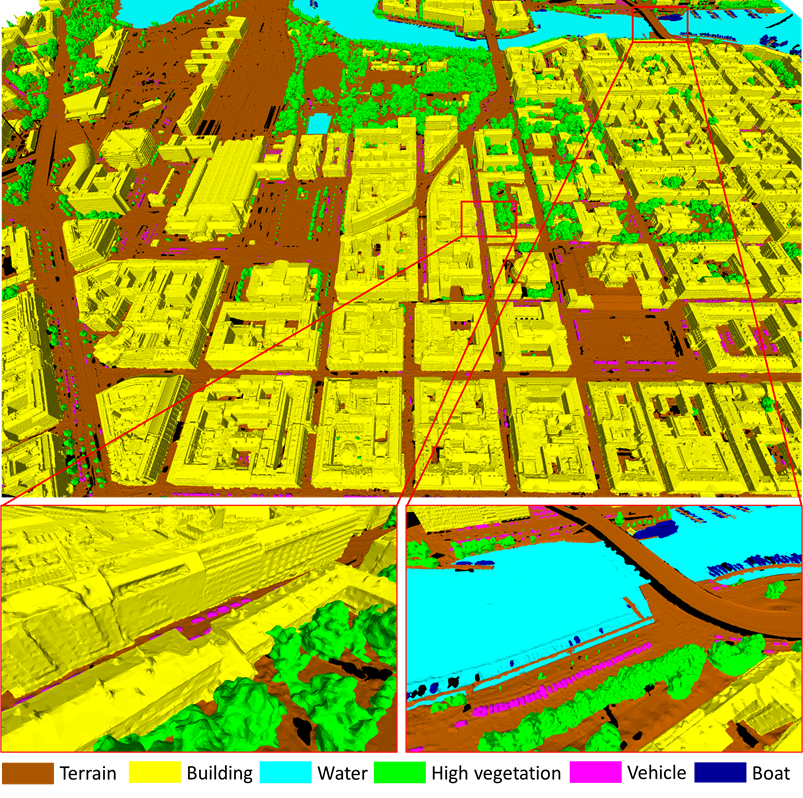
Figure 4: Part of the semantic urban mesh benchmark dataset, showing the semantic classes (unclassified regions are in black).
Data Download
The mesh data can be visualized in MeshLab and our Urban Mesh Annotation Tool. We also provide the sampled point clouds with semantics, colours and corresponding face ids in three sampling density (refer to surface area): 10 pts/m2, 30 pts/m2 and 300 pts/m2. In addition, we only provide the data in PLY format, and the semantic classes and colours are defined as follows:
| Labels | Semantics | RGB |
|---|---|---|
| 0 | unclassified | 0 , 0 , 0 |
| 1 | terrain | 170, 85 , 0 |
| 2 | high vegetation | 0 , 255, 0 |
| 3 | building | 255, 255, 0 |
| 4 | water | 0 , 255, 255 |
| 5 | car | 255, 0 , 255 |
| 6 | boat | 0 , 0 , 153 |
Data Download: SUM Helsinki 3D
Source Code
All of our source code will be available on GitHub.
Source Code 1: Urban Mesh Annotation Tool.
Source Code 2: Semantic Urban Mesh Segmentation.
Labelling Workflow
Rather than manually labelling each individual triangle face of the raw meshes, we design a semi-automatic mesh labelling framework to accelerate the labelling process. Firstly, we over-segment the input meshes into a set of planar segments. To acquire the first ground truth data, we manually annotate the mesh (with segments) that is selected with the highest feature diversity. Then, we add the first labelled mesh into the training dataset for the supervised classification. Specifically, we use the segment-based features as input for the classifier, and the output is a pre-labelled mesh dataset. We then use the mesh annotation tool to manually refine the pre-labelled mesh according to feature diversity. In addition, the new refined mesh will be added to the training dataset in order to improve the automatic classification accuracy incrementally.
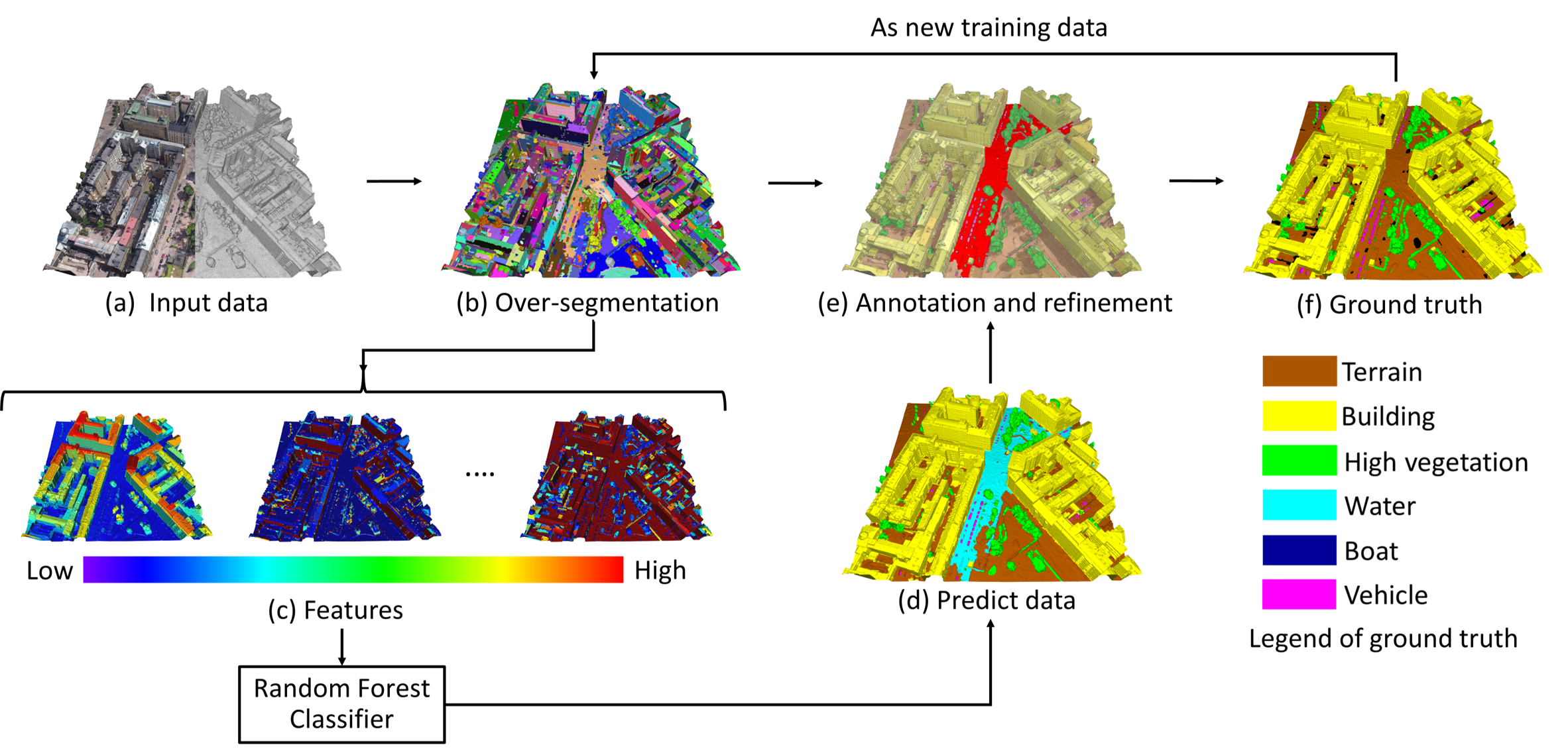
Figure 5: The pipeline of the labelling workflow
Following the proposed framework, a total of 19,080,325 triangle faces have been labelled, which took around 400 working hours. Compared with a triangle-based manual approach, we estimate that our framework saved us more than 600 hours of manual labour.
Comparison of Existing 3D Urban Benchmark Datasets
Urban datasets can be captured with different sensors and be reconstructed with different methods, and the resulting datasets will have different properties. The input of the semantic labelling process can be raw or pre-processed urban datasets such as the pre-labelled results of semantic segmentation. Regardless of the input data, it still needs to be manually checked and annotated with a labelling tool, which involves selecting a correct semantic label from a predefined list for each triangle (or point, depending on the dataset) by users. In addition, some interactive approaches can make the labelling process semi-manual. However, unlike our proposed approach, the labelling work of most of 3D benchmark data does not take full advantage of pre-processing steps like over-segmentation and semantic segmentation on 3D data, and interactive annotation in the 3D space.
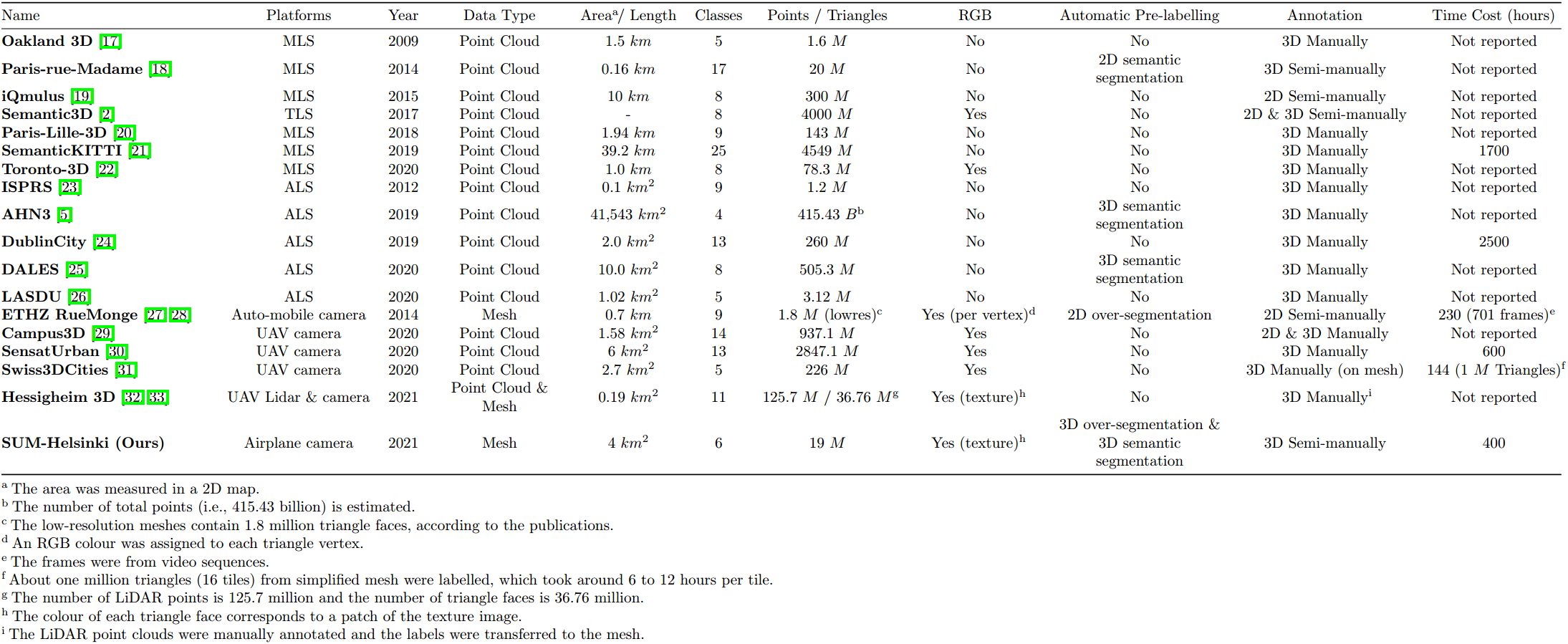
Table 1: Comparison of existing 3D urban benchmark datasets.
Data Split
To perform the semantic segmentation task, we randomly select 40 tiles from the annotated 64 tiles of Helsinki as training data, 12 tiles as test data, and 12 tiles as validation data. For each of the six semantic categories, we compute the total area in the training and test dataset to show the class distribution.
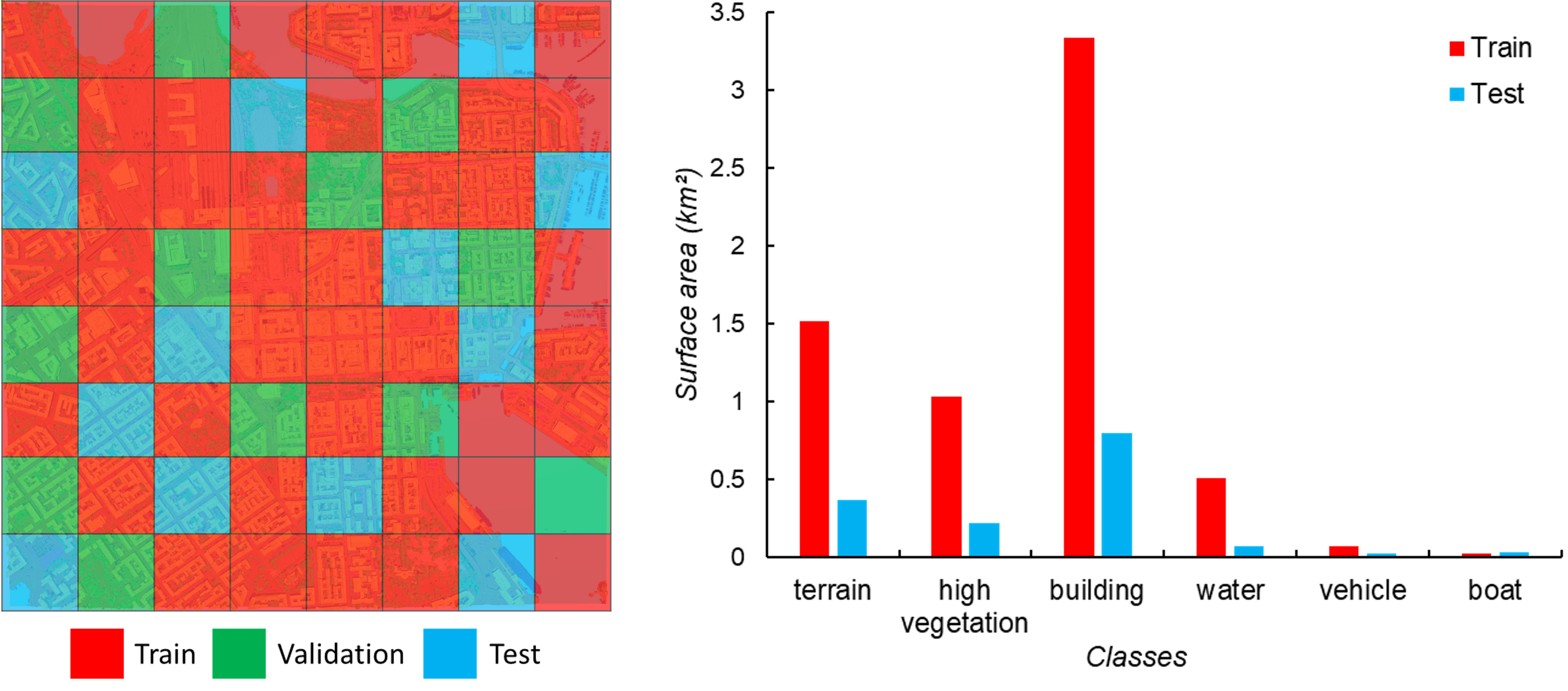
Figure 6: Overview of the data used in our experiment. Left: The distribution of the training, test, and validation dataset. Right: Semantic categories of training (including validation data) and test dataset.
Evaluation
We sample the mesh into coloured point clouds with a density of about 30 pts/m2 as input for the competing deep learning methods. To evaluate and compare with the current state-of-the-art 3D deep learning methods that can be applied to large-scale urban dataset, we select five representative approaches (PointNet, PointNet++, SPG, KPConv, and RandLA-Net), and we perform the experiment on an NVIDIA GEFORCE GTX 1080Ti GPU. In addition, we also compare with the joint RF-MRF, which is the only method that directly takes the mesh as input and without using GPU for computation. The hyper-parameters of all the competing methods are tuned to achieve the best results we could acquire. We achieve about 93.0% overall accuracy and 66.2% mIoU. Specifically, our approach outperforms RF-MRF with a margin of about 5.3% mIoU, and deep learning methods (not including KPConv) from 16.7% to 29.3% mIoU. Compared with the KPConv, the performance of our method is much more robust, and our method is conducted on a CPU and uses much less time for training.
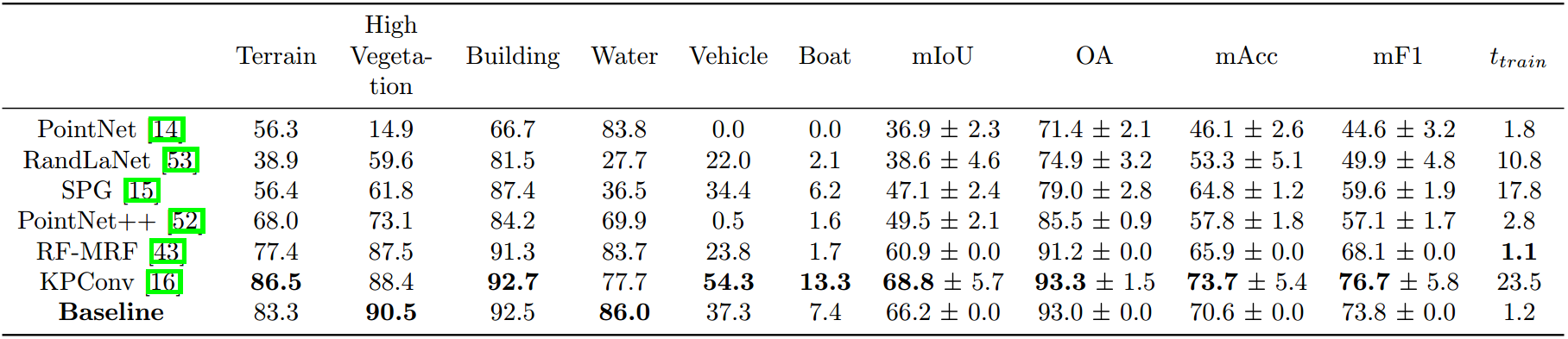
Table 2: Comparison of various semantic segmentation methods on the new benchmark dataset. The results reported in this table are per-class IoU (%), mean IoU (mIoU, %), Overall Accuracy (OA, %), mean class Accuracy (mAcc, %), mean F1 score (mF1, %), and the running times for training and testing (minutes). The running times of SPG include both feature computation and graph construction, and RF-MRF and our baseline method include feature computation. We repeated the same experiment ten times and presented the mean performance.
We also evaluate the performance of semantic segmentation with different amounts of input training data on our baseline approach with the intention of understanding the required amount of data to obtain decent results. We found that our initial segmentation method only requires about 10% ((equal to about 0.325 km2) of the training dataset to achieve the acceptable and stable results. In other words, using a small amount of ground truth data, our framework can provide robust pre-labelled results and significantly reduce the manually labelling efforts.
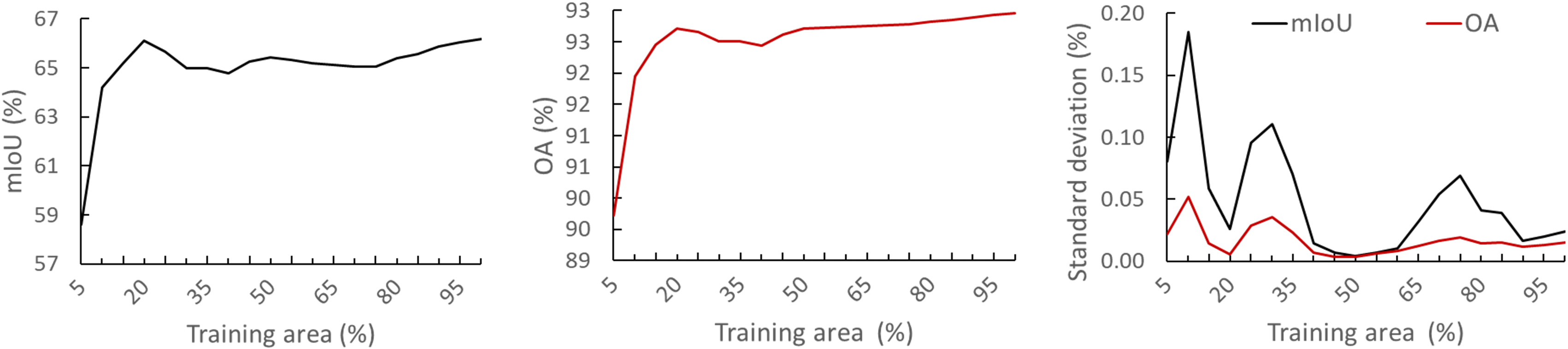
Figure 7: Effect of the amount of training data on the performance of the initial segmentation method used in the semi-automatic annotation. We repeated the same experiment ten times for each set of training areas and presented the mean performance
Video Demo
Citation
If you use SUM-Helsinki in a scientific work, we kindly ask you to cite it:
PDF BibTeX
@article{sum2021,
author = {Weixiao Gao and Liangliang Nan and Bas Boom and Hugo Ledoux},
title = {SUM: A Benchmark Dataset of Semantic Urban Meshes},
journal = {ISPRS Journal of Photogrammetry and Remote Sensing},
volume = {179},
pages = {108-120},
year={2021},
issn = {0924-2716},
doi = {10.1016/j.isprsjprs.2021.07.008},
url = {https://www.sciencedirect.com/science/article/pii/S0924271621001854},
}
Funding


This project has received funding from EuroSDR and support from CycloMedia.
Team




Student Helper
Ziqian Ni, assists in software development, from 2019-07 to 2019-09.
Mels Smit, assists in mesh annotation, from 2020-07 to 2020-09.
Charalampos Chatzidiakos, assists in mesh annotation, from 2020-07 to 2020-09.
Michele Giampaolo, assists in mesh annotation, from 2023-03 to 2023-06.
Sharath Chandra Madanu, assists in mesh annotation, from 2023-03 to 2023-06.