
DDL-MVS: Depth Discontinuity Learning for MVS Networks
Published:
Abstract
Traditional MVS methods have good accuracy but struggle with completeness, while recently developed learning-based multi-view stereo (MVS) techniques have improved completeness except accuracy being compromised. We propose depth discontinuity learning for MVS methods, which further improves accuracy while retaining the completeness of the reconstruction. Our idea is to jointly estimate the depth and boundary maps where the boundary maps are explicitly used for further refinement of the depth maps. We validate our idea and demonstrate that our strategies can be easily integrated into the existing learning-based MVS pipeline where the reconstruction depends on high-quality depth map estimation. Extensive experiments on various datasets show that our method improves reconstruction quality compared to baseline. Experiments also demonstrate that the presented model and strategies have good generalization capabilities.
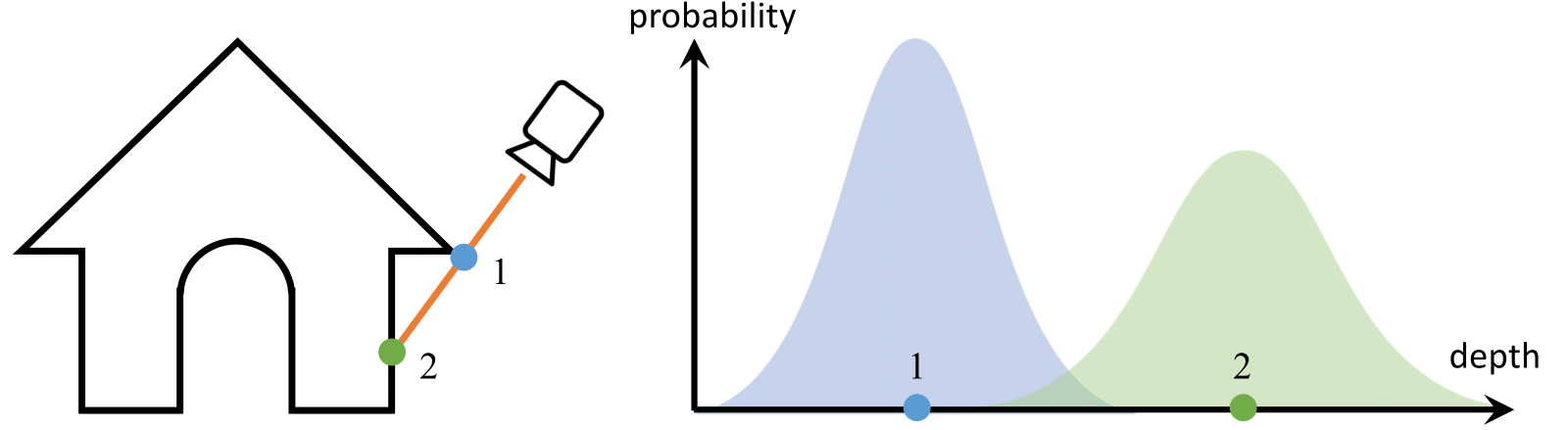
We propose to estimate depth as a bimodal univariate distribution. Using this depth representation, we improve multi-view depth reconstruction, espe- cially across geometric boundaries.
Pipeline
An overview of the proposed multi-view depth discontinuity learning network that outputs depth and edge information for each pixel. The brown arrows represent input feed and blue arrows represent pipeline flow. We first extract multi-scale features from color images with FPN [35] alike auto-encoder. Then we feed extracted features and camera parameters to the coarse-to-fine PatchMatch stereo module to extract the initial depth map. Using the initial depth map and RGB pair, our network learns bimodal depth parameters and geometric edge maps. We use mixture parameters and photo-geometric filtering to compute our final depth map. The edge map visualized here is negated edge map (for a clear view)
Comparison with COLMAP and PATCHMATCHNET
Comparison with the baseline

Comparison between our method and the baseline method PatchmatchNet on a set of scenes from the Tank and Temples dataset. For each scene, the top row shows the results from PatchmatchNet, and the bottom row shows the results from our method. A zoomed view of the marked image region is shown on the right of each result.