Scribblings
Collection of some quick resources/scribblings
11-April-2023
OpenFOAM scaling [FOOTE & DELFT BLUE]
To understand the best practice for using OpenFOAM-v2106 on the two computing clusters of our choice i.e., Foote .or. Delft Blue, we ran three cases with varying problem sizes that represent prototypical problem sizes used in urban canopy flows. The details of the grid can be seen in table below, where the numbers correspond to the total cell count.
| Case Name | Grid Size [Total] | |||
| Small | 4.8 Million | |||
| Medium | 20.3 Million | |||
| Big | 66 Million |
Details of the computing environments
- Foote – This is an AMD based system that hosts two AMD EPYC 7302 16-Core Processor with a CPU clock of 1500 MHz. The server is equipped with 252 GB of memory with about 2GB available on SWAP.
- DelftBlue – This is an Intel based computing cluster where each node hosts two Intel XEON E5-6248R 24-Core Processor a CPU clock of 3000 MHz. Each node is equipped with 196 GB of memory. In the following sections, we first present the scaling results on Foote which is a stand-alone AMD based server.
- - - - - - - - - - Foote vs. Delft Blue - - - - - - - - - -
The strong scaling results are testing using the simpleFoam steady state solver for the various cases presented below. It is important to note that all the velocity solvers are set to smooth Solver while two pressure solvers were considered (i.e., GAMG and PCG). Since most of the computational effort in Navier-Stokes solvers is focused on the elliptical Poisson solver, any scaling differences can be attributed to the pressure solver approach used for each of the case. It was observed that for the case big, GAMG vastly outperformed PCG due to the multi-grid nature of the iterative solver. As a result, for all the cases discussed below, only the GAMG solver was considered as it leads to lower absolute time per iteration. Figure 1 shows the scaling results for the three cases listed in the table above. The speedup on the Y-axis is defined by
\[S \equiv \left( \frac{t_{i=1}}{t_i}\right) N_{i=1},\]where \(S\) is the speedup, \(t_i\) is the average wall clock time for \(i\) CPUs, and \(N_{i=1}\) is the lowest number of CPUs for a given test case. Here \(N_{i=1}\) is used to scale the speedup since running the case in serial can take an unreasonably large wall clock time.
In figure 1, the black lines correspond to the cases run on Foote while the magenta lines correspond to the cases that are run on DelftBlue. For case small, the strong scaling results are identical, and the overall trend is similar to case big. As for case medium, there is some super-linear scaling observed for 16 CPUs with a maximum speedup of 25 observed. However, beyond 16 CPUs the speedup seems to saturate and communication between the CPUs seems to dominate the parallelism thus resulting in poor parallel performance beyond 16 CPUs for this case.
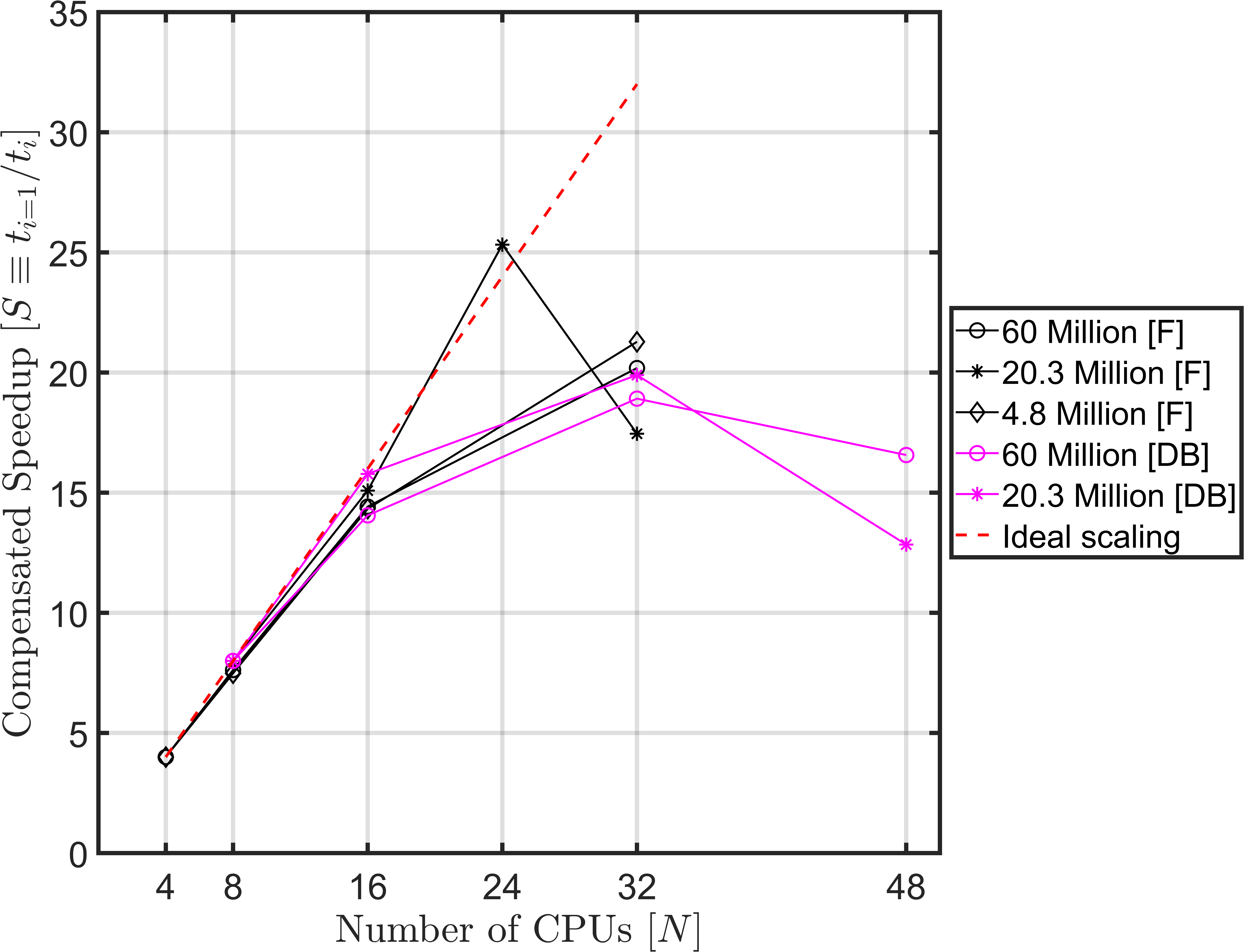
Comparison of the scaling for all the cases suggests a similar overall behavior with some differences observed between the two computing frameworks detailed above. It is important to note that the AMD server performs better for all the cases shown in figure 1 for the cases under consideration. In summary, it is observed that for the GAMG algorithm and simpleFoam solver, using 32 CPUs for a problem size larger than 25 Million grid points is acceptable. While it is recommended to use 16 CPUs for problem sizes smaller than 25 Million grid cells.
- - - - - - - - END - - - OF - - - POST - - - - - - - -