MSc Geomatics GEO1008 February-April 2019
Assignment 4: Metadata
Deadline is Monday 18 March 2019 at 8:30.
Late submission? 10% will be removed for each day that you are late.
You’re allowed for this assignment to work in a group of 2 (and thus submit only one report for both of you). If you prefer to work alone it’s also fine (but we don’t recommend it).
- Overview: From JSON to ISO Compliant XML
- What you need to do to start
- Source datasets
- Required categories
- Validation of the results
- Marking
- What to submit and how to submit it
Overview: From JSON to ISO Compliant XML
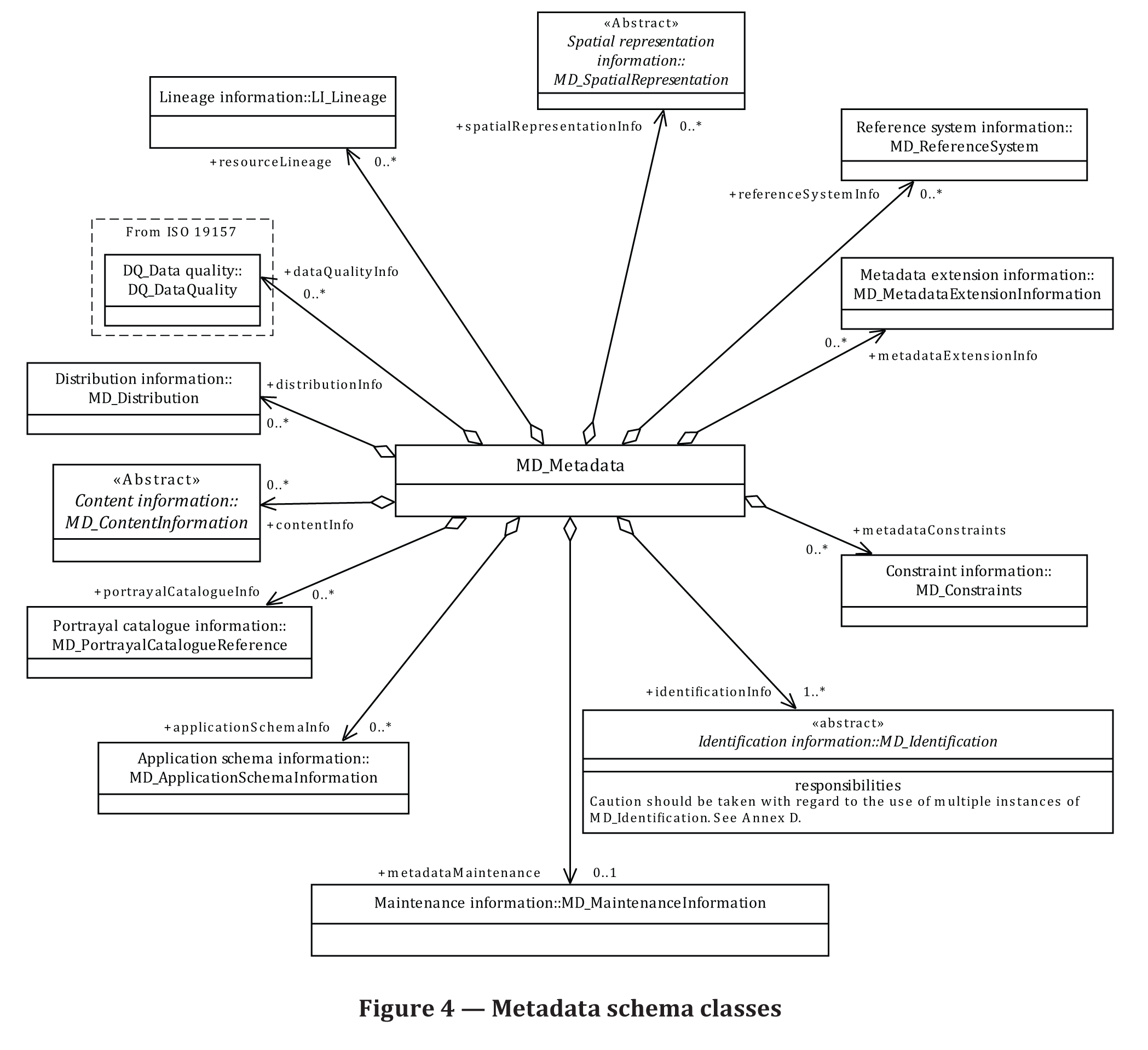
The aim of this assignment is to create ISO 19115-compliant XML metadata, as defined by ISO 19139, from input JSON metadata. This will be done by automating the process by creating a script that parses a JSON file, searches for the necessary fields, and outputs an XML file.
You will be working with data from the South Australian Government Data Directory; the metadata and the corresponding spatial datasets are all publicly available via data.sa.gov.au/.

You are allowed to use the tool(s) that you want, a mix of software is also possible, but be clear in the report what you used for which task(s). However, we strongly recommend that you use Python for your script since there are many libraries that will be useful and we believe this is a great language to know well for Geomatics engineers.
What you need to do to start
- skim the ISO 19115 documentation and the ISO 19139 documentation, particularly the appendices which contain examples. This can be obtained with your NetID via NEN. (note you must be on campus or using a VPN to access NEN)
- download the NOAA ISO 19115:2003 Geographic Information - Metadata Workbook to familiarise yourself with the implementation and possible categories/issues.
- examine libraries that can help you process JSON and XML.
Source datasets
You should utilise the metadata from datasets available from the open data of the Government of South Australia. Note: the Government of Australia is trying to merge their different open data websites into one, there is a beta website being tested but the beta website does not yet host the metadata therefore if it tries to redirect you: don’t follow! The website should look like this:
…not like this!:
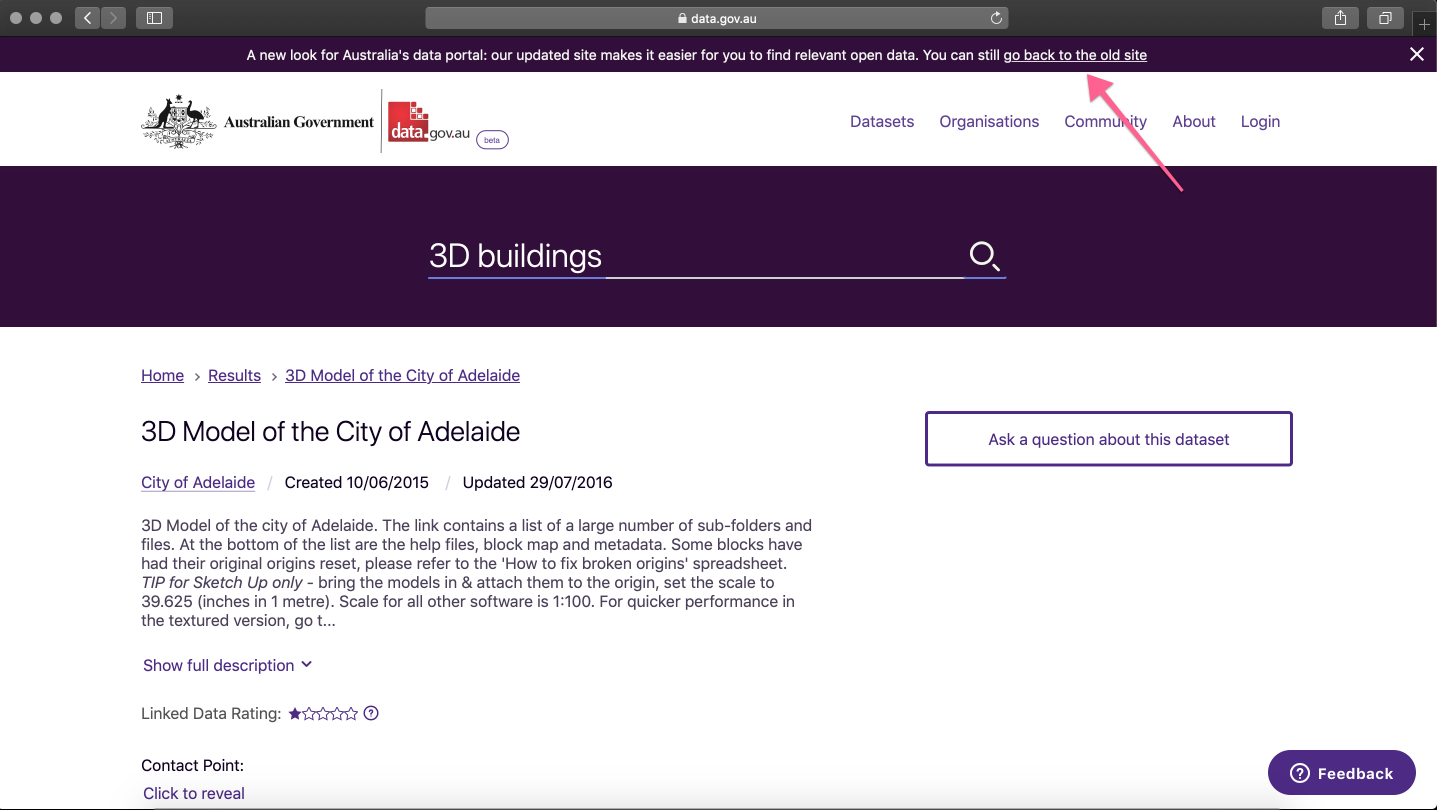
They provide their metadata in three formats already: JSON, XML and RDF. Note: don’t confuse the JSON metadata (located in the upper right corner) with any datasets that are provided in GeoJSON (located in the main body of the page)!
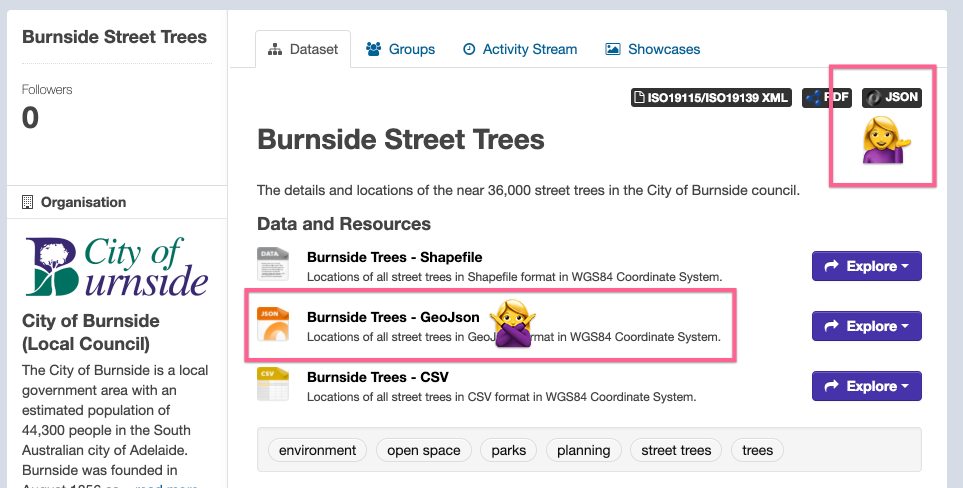
Feel free to examine how they format their XML documents but simply copying their format will not earn you full marks, furthermore they include certain custom attributes in their XML implementation (which may or may not be ISO compliant). You have to choose yourself the datasets you would like to work with, and you need to download them yourself. (Testing your script with more than one dataset is a good idea.) We will test your script with several random files so make sure you test your script with several datasets.
Sample dataset: Burnside Street Trees
Make sure you filter for spatial data specifically, and it would be better to avoid raster data as it has a further ISO extension.
Hint: It may be helpful to format the JSON file to better understand the file structure, this website has a good one: JSON Formatter & Validator. The Firefox browser has native JSON support: just drag’n’drop a JSON file to see and browse it like a tree!
Required categories
We have selected a subset of the possible ISO categories (from the former core and current ‘Metadata for Discovery’ table). All of the following categories must be accounted for:
- Dataset title
- Dataset reference date
- Dataset responsible party
- Geographic location of the dataset
- Dataset language
- Dataset topic category
- Spatial resolution of the dataset
- Abstract defining the dataset
- Distribution format name and version
- Additional extent information
- Spatial representation type
- Reference system
- Metadata file identifier
- Metadata standard name
Note that there may be missing categories in some of the metadata, ensure you can deal with situations where information is missing. Make sure to use common sense for missing categories… Also be aware that category names in the JSON files might not be the same names used by the ISO standard, you need to investigate this yourself!
Validation of the results
Creating valid output XML is not an easy task, and many countries customise the standard to be applicable to their specific country or organisation.
There are many XML and ISO 19115 specific validators online, feel free to use one of your preference, just make sure to discuss in your report what you used.
A generic XML validator can be used here: XML validator from freeformatter.com This will require the XSD for ISO 19139 which can be obtained here: ISO 19139 XSD
Marking
- 40% for the quality of the report you submit
- 60% for the automatic metadata conversion script
The report should be a scientific one, i.e. with an introduction, a problem description, methodology, and discussion, etc. We expect around 10 pages with figures.
For the methodology, you can put (parts of) your code to describe what you’ve done. Focus on explaining why you used the libraries that you used and any decisions that you made for the final output. Focus on the parts where you had the most difficulties, and describe the solution you designed (including discussions of the potential alternatives). Hint: discussing approaches that failed can make for some great discussion points.
While you have freedom for the discussion section there are a couple of issues that you must include to receive full marks:
- Were you able to validate your results? If yes, how? How confident are you that your results are ISO-compliant? If no, why not? What tools would you need to successfully validate your results? Discuss and argue why the file you submitted is ISO-compliant, or not.
- How would your methodology be different if you were moving from XML to JSON? Can your script be easily adjusted to do the inverse? What are the advantages of using one format over another?
- What did you do, or what would you do to account for categories that are misnamed, misspelled, alternatively spelled or referred to by an alternative name?
Note: You must include those issues but you should include other discussion points as you see fit. You have to be critical about the choices you made (i.e. discuss the advantages/disadvantages of your methodology, compared to other choices you could have made). The general report is worth 25% and each of the above discussion points is worth 5% each.
Your script should be well commented and neat, we should be able to easily understand what each part is doing. This way, even if we fail to run your script we should be able to parse it to understand what you are doing. At the same time, you should anticipate situations in which your script may fail and find solutions to avoid crashing your script.
What to submit and how to submit it
You have to submit (in one ZIP):
- a report in PDF format (not in Microsoft Word please);
- your script, probably a Python one, but other languages accepted;
- provide instructions regarding how to run the script as a README.txt;
- one output XML file created with your script;
- the original JSON file that you used as input to generate the XML.
Do not submit your assignment by email, but upload the requested files in one ZIP to this Dropbox file request page. Make sure that you put the full name of one of the member of the team (only one is sufficient).
You’ll get a confirmation email when everything has been successfully uploaded, keep it in case things go wrong.

last updated: 03/11/19 (15:09:18)